Some of you might remember our Seamless Concurrency article, about how a region-aware language could safely add multi-threading with just one simple parallel keyword.
That was just scratching the surface of what's possible!
There's so much incredible potential in the realm of parallelism:
- Threading models that have the benefits of both goroutines and async/await. 0
- Concurrency models that are so reliable that it's literally impossible to crash them them, which enable nine nines: uptime of 99.9999999%. 1
- Ways for certain patterns of code to go over 100x faster than the most well-optimized CPU-based program.
Today, we're going to talk about that last one!
It's sometimes tempting to think that we've reached the end of programming languages, and that today's languages are as good as it gets. I'm here to tell you that we ain't seen nothin' yet! 2
Welcome to the Next Gen Language Features series, where we talk about surprising language features that are on the horizon, and could soon change the way we program.
I'm referring not only to Zig's colorless async/await, but also what lies beyond it!
Lookin' at you, Pony actors!
If you want a real taste of what's coming from the languages realm, check out r/programminglanguages, r/vale, and my RSS feed where I post articles like this pretty often.
GPUs' Hidden Powers
If you have a late 2019 Macbook Pro, you have 6 x 2.6ghz cores, totaling to 15.6 ghz.
However, there are 1,536 other cores hidden on your machine, each running at around 1.3 ghz. These are in your GPU, and they're usually used to play your movies and make your games look good.
That's a lot of untapped computational power. Imagine if you could harness that power for more than graphics! 3
A couple decades ago, folks at Nvidia thought the same thing, and created CUDA, giving us unprecedented control over that raw power.
With CUDA, one can write C++ code that runs on the GPU. I'm not talking about shaders, which only do very specialized things, I mean general purpose, real C++ code. One can even use it to write a ray tracing program that produces this image: 4

The GPU isn't a silver bullet, but it can be used for many kinds of code 5 where we can do a lot of calculations in parallel because there are no dependencies between them. This kind of calculation is very common in some fields (like games and simulations), though not very common in others (like GUI apps and CRUD servers).
While the rest of us weren't looking, GPU programming has made incredible strides. While we were struggling to get 10x speedups on our mere 6 CPU cores, people have been using GPUs to get 100-1000x speedups.
However, it was always very tricky to get it working. One had to have exactly the right hardware, exactly the right drivers, it only supported C and C++, and it only worked on odd days of the month, when Venus was aligned with our ninth planet, Pluto.
Alas, kind of a mess.
Machine learning is a popular use case, and some people have even used it for climate, weather, and ocean modeling.
I made this in 2012!
This kind of code is often often referred to as "embarassingly parallel".
A Mess, Perhaps
But maybe there's some order emerging out of the chaos.
The Khronos Group created something called SPIR, to serve as a common protocol between all of the different platforms:
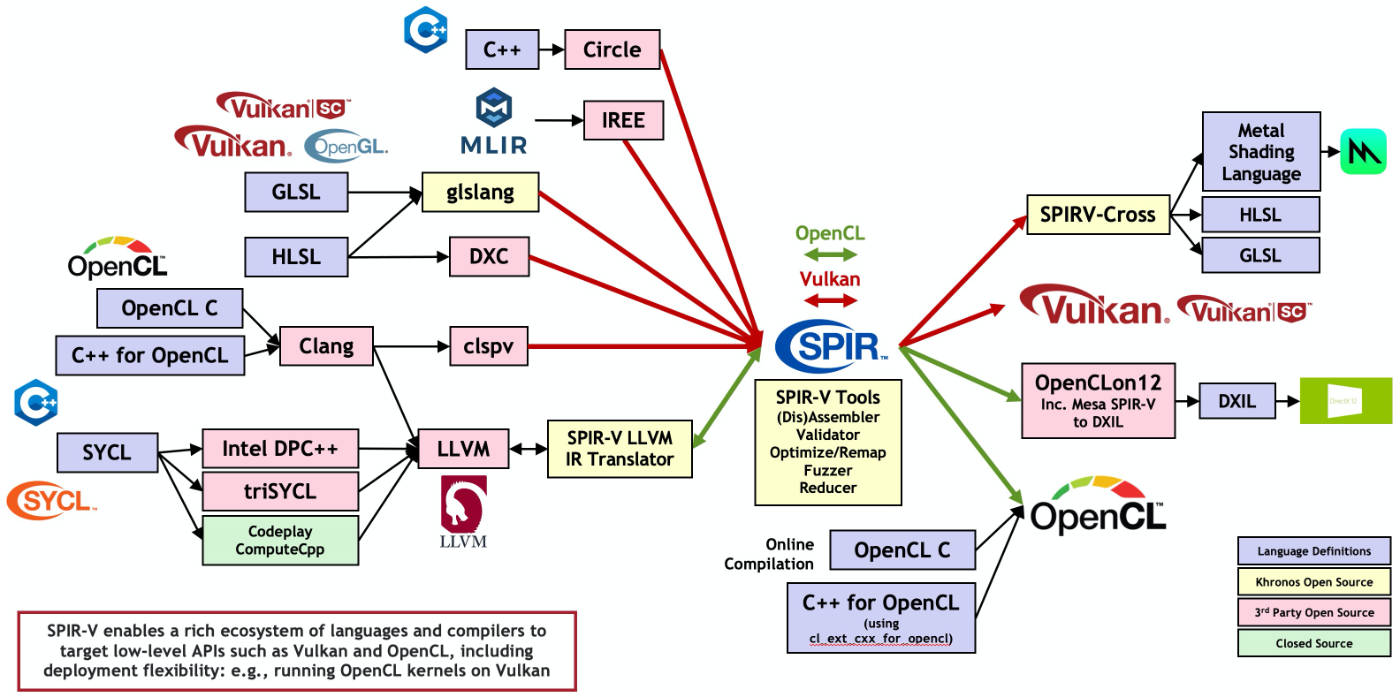
Common protocols often spark firestorms of innovation.
My favorite example of a common protocol is LLVM, an easy assembly-like language that comes with many "backends" that can translate to any architecture under the sun, such as x86 or ARM. Languages only need to compile to the LLVM language, 6 and then let the LLVM backends do the rest. Without LLVM, we might not have languages like Cone, Zig, Nim, Rust, Lobster, Odin, or our favorite, Vale. 7
Speaking of LLVM, if you look really closely, there's a "SPIR-V LLVM IR Translator" box in the above image. It makes you wonder: could general purpose languages take advantage of that?
More specifically, they call the LLVM API to construct an Abstract Syntax Tree in memory, and then LLVM will translate that.
Though I'm probably a bit biased. Just a bit.
Parallelism for the User
The underlying technology is only half of the story. For something to take off, it needs to be intuitive.
Luckily, parallelism is becoming more and more intuitive.
- C's OpenMP has made parallelism as easy as adding a single line to a for-loop.
- Go raised channels to a first-class citizen in their language, emphasizing message passing in an otherwise imperative language.
- Languages like Pony and Rust have shown that, with some investment, we can have code free of data races.
Truly, parallelism is getting more and more within reach.
On top of that, it might be possible to get the best of all worlds, like described in Seamless, Structured, Fearless Concurrency.
How they might Meet
I would love to see a language offer one easy keyword, to launch a lot of code in parallel on a GPU. Perhaps something like:
exported func main() {
exponent = 3;
results =
parallel(gpu) foreach i in range(0, 5) {
pow(i, exponent)
};
println(results);
}I think languages could make some big strides here.
However, there are some open questions and challenges between here and there.
Challenges
That all sounds great, but how can we make it happen? There are a lot of challenges between here and there.
Shipping Data to the GPU
There's a cost to send data to and from the GPU.
Let's pretend we have 10 GPU cores, and we have this data:
and we want to double each number, to get:
we might use this code:
results =
parallel(gpu) foreach x in data {
x * 2
};If we have 2 CPU cores, and 10 GPU cores, the GPU could run this 5x faster, right?
Unfortunately, it's not that simple: we need to send that data array to the GPU first. And then afterwards, we'll need to send that results array all the way back to the CPU!
Sending data between the CPU and GPU can take a long time, so it might be faster to just use our 2 CPU cores.
Imagine ten thousand Norwegian horseman traveling for two weeks to Alaska, each with a simple addition problem, like 5 + 7. Ten thousand Alaskan kindergarteners receive the problems, spend three seconds solving them in parallel, and the ten thousand horseman spend another two weeks returning.
It would have been faster to have one Norwegian kindergartener do the ten thousand additions!
If we need more calculations on less data, the GPU becomes much more viable. A user needs to balance it.
However, there might be some interesting tricks to pull here.
- We might be able to eagerly ship some data to the GPU before it's needed, like how video streaming loads data ahead of time.
- After shipping that data to the GPU, we can send updates as they happen. 8
- We might chain different functions together into a pipeline, such as with Futhark's Fusion.
- This means we dont have to ship data back to the CPU and then to the GPU again for the next phase; the GPU can directly hand one function's output to another function's input.
- This is similar to how some shader frameworks allow us to piece subshaders together.
Futhark is also helping with this, by giving us building blocks that are naturally more parallelizable and have less branching, second-order array combinators (SOACs) such as map, reduce, scan, filter, reduce_by_index.
I suspect languages will become smarter about eagerly streaming data to the GPU. We're starting to see the early signs of this in CUDA 11.3, which adds some features for streaming memory to the GPU at the right time.
This is often done with Vertex Buffer Objects, so we know it's possible.
Warps
The second big challenge is that CPU parallelism is very different from GPU parallelism. The user will need to know when their parallelism isn't suited for the GPU.
In CPUs, core A runs code X, while core B runs code Y. You can have twelve different cores running twelve different functions. They're completely separate
Nvidia GPUs have hundreds or thousands of cores, divided into groups of 32 cores, called "warps". 9 All cores in a warp will all be executing the same code, similar to how SIMD runs the same instructions on multiple data.
This system has benefits, but also drawbacks, explained below.
In keeping with the 3D graphics tradition of clear and consistent naming, the SIMD concept is called SIMD groups on Metal, warps on Nvidia, wavefronts on AMD, and subgroups on Vulkan.
Branching in Warps
Let's pretend our GPU has 4 cores per warp, and we want to do some operations on this data:
We'll be doing all these operations will happen in one warp, because there are 4 cores per warp, and theres 4 pieces of data here. So far so good.
But let's say we want to halve the even numbers and triple the odd numbers:
We might use this code:
results =
parallel(gpu) foreach x in data {
is_even = (x % 2 == 0); // A
if is_even {
x / 2 // B
} else {
x * 3 // C
}
};This is what happens:
- All cores will run line A.
- Cores 1-2 will run line B. Cores 3-4 will wait for them to finish.
- Then, cores 1-2 will wait for cores 3-4 to run line C.
As you can see, the warp only runs one instruction at a time, for whatever cores might need it. The other cores wait.
If the user doesn't pay attention to their branching, they could get pretty bad performance.
In practice, the user can restructure their program so that all cores in a warp will take the same branch, and there will be no waiting.
This might have two warps doing a lot of waiting:
But this input will have two warps doing zero waiting:
The user needs to be aware of this, and use techniques like that to organize their data.
Maybe languages could help with this. Perhaps a language could make it easier to bucket-sort our data en route to the GPU, so it branches less.
Or, perhaps a language could make it easy to flip back and forth between layouts, so we can experiment and profile to see what's fastest on the GPU. For example, Jai is adding a feature to change the layouts of structs and arrays for better optimization. 10
Specifically, it allows changing an array-of-structs into a struct-of-arrays.
Recursion and Indirect Calls
Recursion is possible on GPUs, but it isn't advisable. Same goes for virtual calls, such as through traits, interfaces, or base classes.
Luckily, there are some languages that give the user very precise control over what code is allows to use recursion or indirect calls. For example, Zig tracks recursion. Perhaps a language could use a mechanism like that to keep recursion and indirect calls at bay, to better run code on the GPU. 11
It would be interesting as well if a compile could also find a way to convert recursive functions into non-recursive. There's probably an algorithm that can do something like that by using stacks.
Registers
GPUs have a finite number of registers. Using less registers will often make GPU code run faster. Fine-grained control is important here.
Any low-level language would do well here, as they give very fine-grained control. However, I think C and Zig have a powerful advantage here, by embracing undefined and implementation-defined behavior. This allows these languages to harness platform-specific behaviors for maximum speed.
Other Challenges
That seems like a lot of challenges! And there are even some more past that. One might think that there's just too many challenges, and it will remain difficult to use the GPU forever.
But the same thing was true of hard drives, CPUs, peripherals, you name it. Abstractions will emerge, patterns will arise, protocols will be standardized, and we will find ways to more effectively harness more GPUs. The question is just how fast we get there.
Promising Languages
There are some really promising languages that could bring GPU programming to the mainstream one day.
Cone offers a borrow checker on top of not only single ownership but also RC, GC, and user-defined memory management models. This could allow us to more easily control what memory is on the GPU and when.
Vale's plans for Seamless Concurrency could easily lead to GPU execution, and its plans for first-class allocators could help with eagerly shipping data to the GPU.
Zig's low-level precision makes it perfect for writing code on the GPU, where every single register matters. Plus, its lack of interfaces/traits and restrictions on recursion could be invaluable for running code on the GPU where stack space is limited.
Rust adds memory safety with very little run-time overhead, 12 which could be a nice benefit for code on the GPU, where memory unsafety can be tricky to debug.
Futhark excels at running user code on the GPU already! I could imagine Futhark getting some nice integrations with mainstream languages, to bring GPU programming to the masses.
MaPLe is extending SML to add fork-join parallelism, for much easier multi-threading. It already gives the user the right building blocks, and if it adds support for the GPU, I think it could work really well.
But any language could make strides here! I hope that we don't all just sit back and wait for existing languages to innovate here. If you have an idea on how we can more effectively harness a GPU, make a language and show it to the world! Or maybe fork an existing language, like Vale, Zig, or D. And if you need any pointers on language design, come to the Vale discord server and we'd be happy to help however we can, and share our code and designs for implementing some of the ideas described here.
In practice, Rust's memory safety primarily comes from the borrow checker which has no overhead, and when an object needs to be reachable from multiple places, we fall back to arrays and hash maps which each have little performance cost, relative to RC or GC.
Conclusion
I hope that you come away from this article seeing the vast potential waiting to be tapped, and how a language might bring incredible parallelism to the mainstream.
Who knows, in ten years, we might even have a language that can enable Entity-Component Systems on the GPU. Wouldn't that be incredible?
Thanks for visiting, and I hope you enjoyed this read!
In the coming weeks, I'll be writing more about how upcoming languages use regions to give them speed and fearless concurrency while remaining simple. Subscribe to our RSS feed or the r/Vale subreddit, and come hang out in the Vale discord!